Three generation modes
Custom Voice, Voice Clone, and Voice Design with model-aware compatibility checks and one-click switching.
Open source, local-first, privacy-centered
PrivateVoice generates natural speech fully on your machine with Qwen3-TTS. Clone voices, design new voices, and export in WAV or MP3 while keeping your data local.
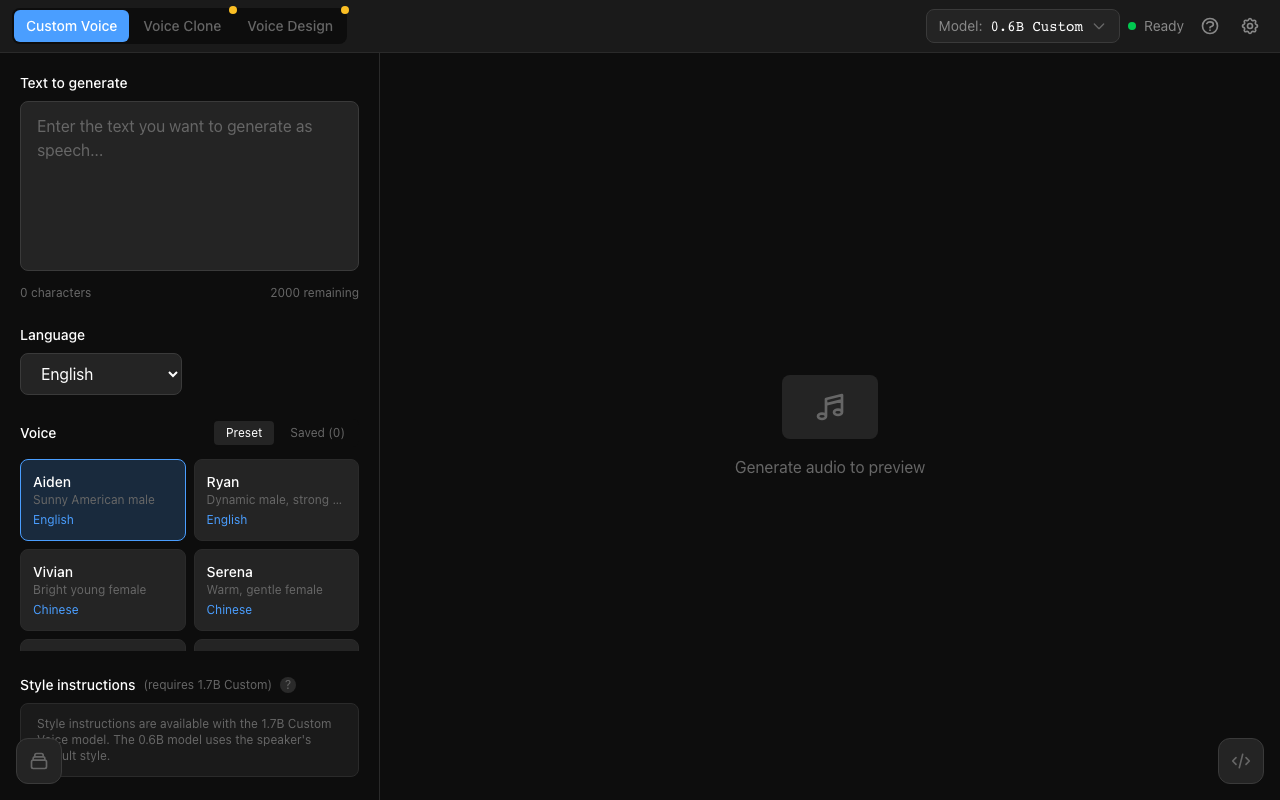
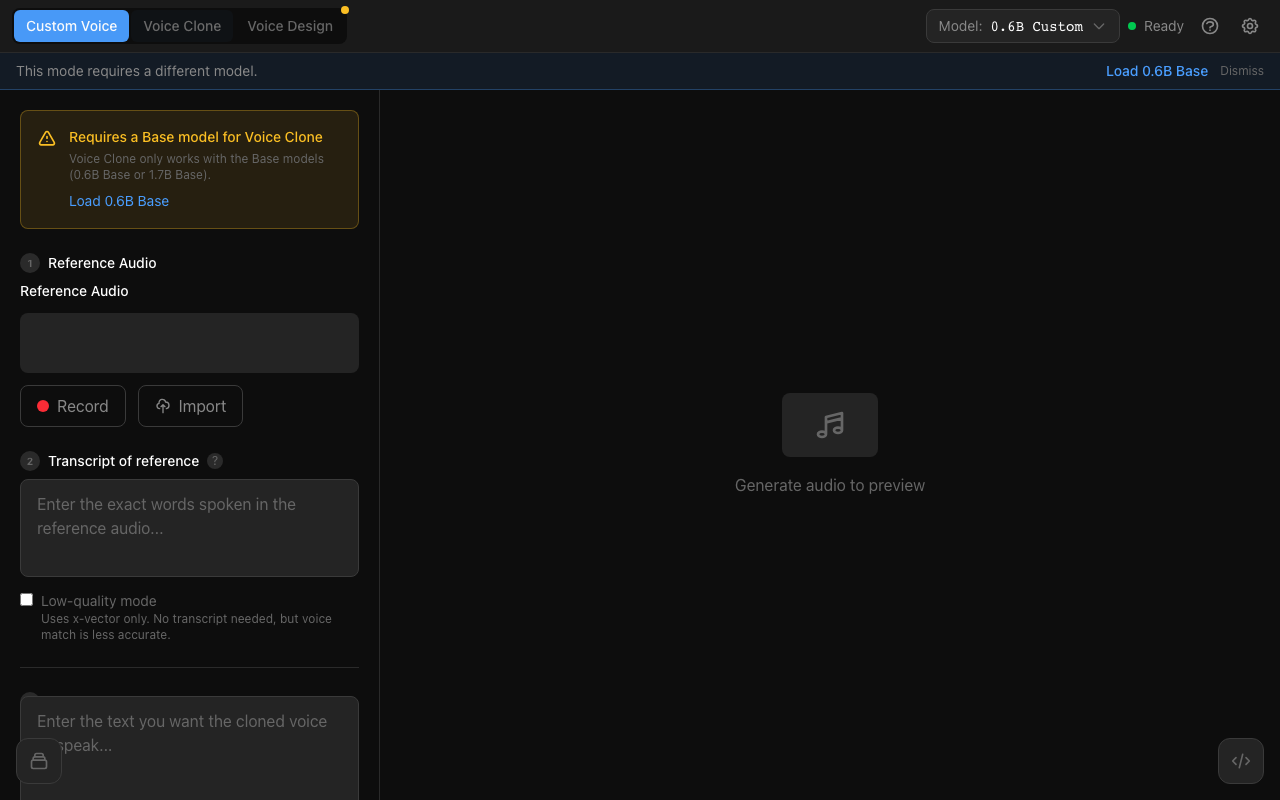
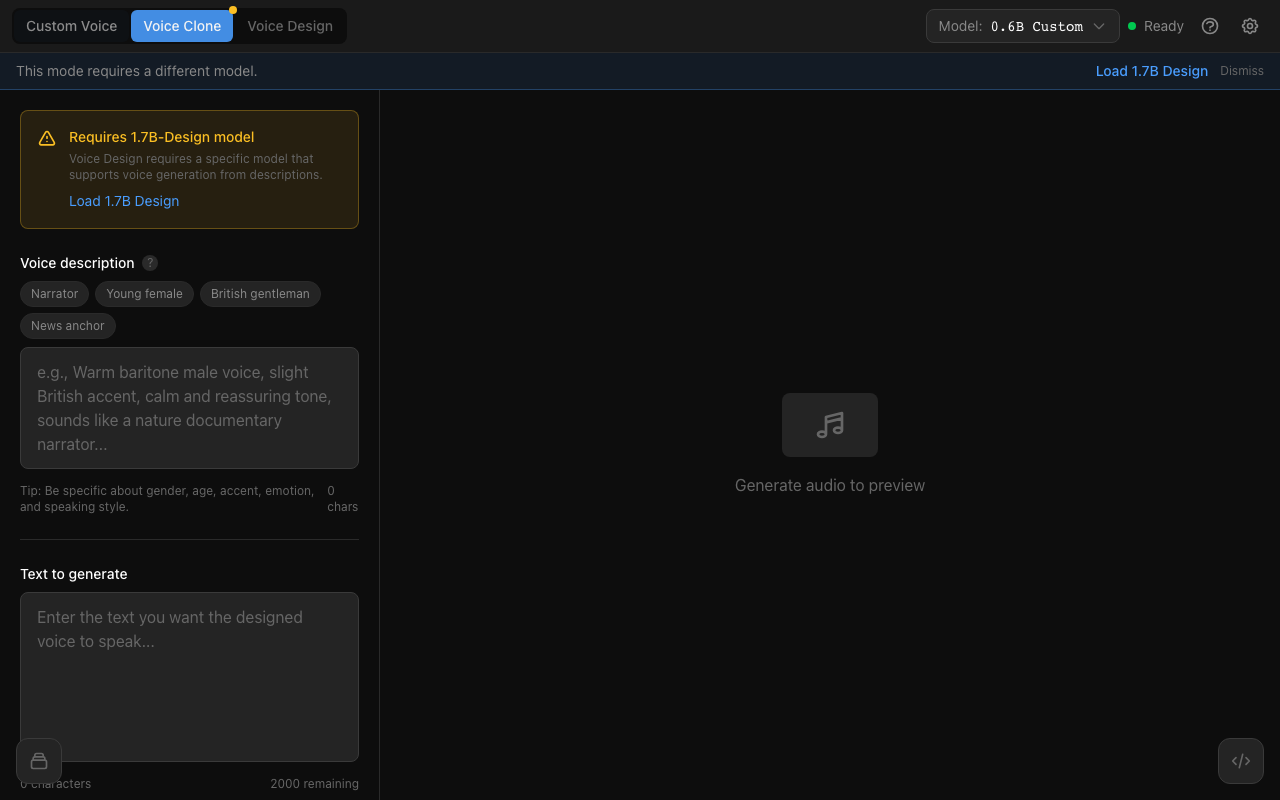
Custom Voice, Voice Clone, and Voice Design with model-aware compatibility checks and one-click switching.
Use optional seed controls across modes for reproducible runs on the same model and hardware profile.
Fine-tune WAV sample rate (8k to 48k + Native) and bit depth (16/24/32-bit PCM) for single and batch exports.
First launch experience
PrivateVoice ships as a lightweight desktop install. On first run it detects hardware, provisions Python 3.11 via
uv, installs dependencies, and starts the local API on 127.0.0.1:8765.
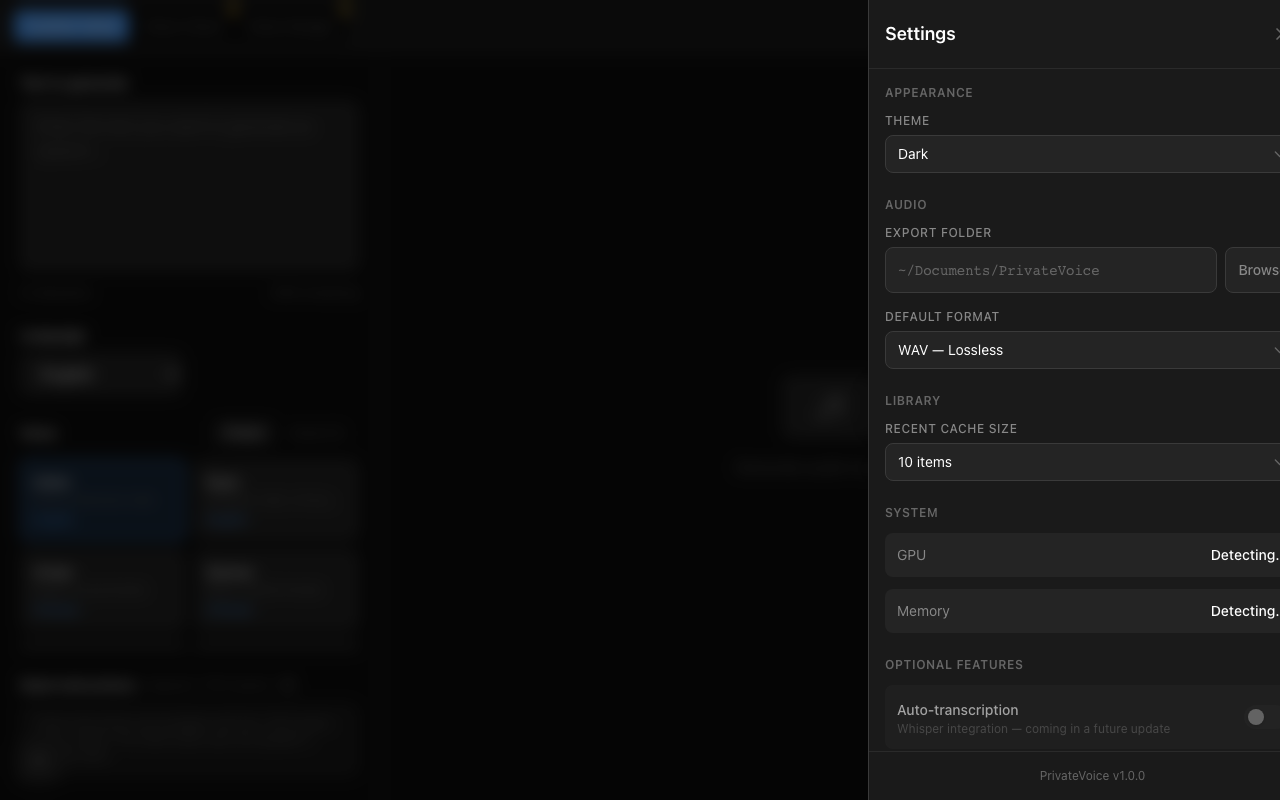
Inference stays on-device. Network access is only needed for setup-time dependency and model downloads. Normal generation runs locally with no cloud API requirements.